파이썬을 이용하여 이미지에서 텍스트 추출하기
1. 개요
1.1 목적
-
이미지에서 텍스트를 추출한다.
1.2 도구
-
언어 : 파이썬 v3.8 (내 PC에 설치되어 있어서)
-
라이브러리 : OpenCV, pytesseract (내 PC가 64비트이므로 가능한 64비트 모듈을 이용)
2. Tesseract를 이용한 텍스트 추출 (OCR)
2.1 Tesseract 소개
tesseract-ocr/tesseract
Tesseract Open Source OCR Engine (main repository) - tesseract-ocr/tesseract
github.com
- Tesseract는 텍스트 인식 (OCR)을 위한 오픈소스로 아파치 2.0 라이선스를 다른다.
- 리눅스, 맥, 윈도우 등 다양한 플랫폼을 지원한다.
2.2 Tesseract 설치
- Tesseract의 윈도우 버전은 Cygwin, MYS2 등을 이용할 수 있으나, 빠르게 진행하기 위하여 Winodws 설치 버전을 이용한다.
- 최신 기능과 데이터를 사용해 보기 위하여, 5.0 알파 버전 64비트를 이용해 보려 했으나,
'한글 훈련 데이터'가 v4.0을 기준으로 준비된 것으로 판단하여, 4.0 버전을 이용하기로 한다. - 훈련 데이터 관련 사항은 '훈련 데이터 파일'에서 확인할 수 있다.
- 'Uninstall 시 설치된 폴더 모두가 삭제되므로 새로운 폴더를 만들어 설치'하라고 권고한다.
- 설치 파일 다운로드 경로 : https://github.com/UB-Mannheim/tesseract/wiki
UB-Mannheim/tesseract
Tesseract Open Source OCR Engine (main repository) - UB-Mannheim/tesseract
github.com
- 윈도우 v4.0 (64비트): https://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-w64-setup-v4.1.0.20190314.exe
- 설치 과정은 간단하다. 다만, 설치 옵션 중 한글 관련 사항이 있다면 모두 설정하기로 한다.

- 필요할 경우 PATH에 등록하여 tesseract를 어떤 디렉터리에서도 사용할 수 있도록 구성한다.

- 이제 명령창(CMD)에서 tesseract를 실행하며, 설치와 실행이 잘 되는 것을 확인한다.
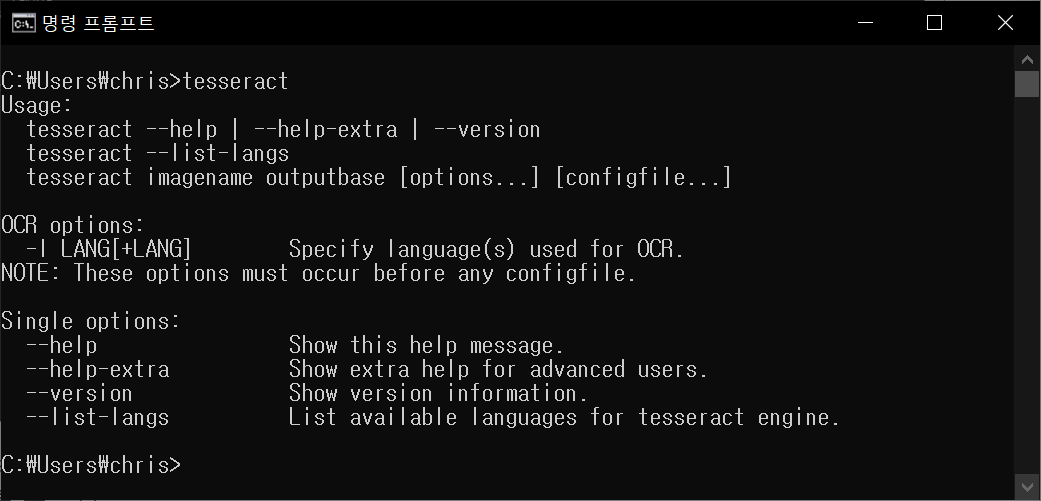
2.3 Tesseract 사용해 보기
- tessertact --help-extra 옵션으로 자세한 도움말을 확인한다.

- tesseract --list-lang 옵션으로 지원하는 언어를 확인한다. (설치 옵션에서 hangul을 선택했다)

- 테스트를 위한 이미지를 준비해 본다.

- 크기와 모양이 다양하게 배치되어 있으니, 명령 옵션으로 --psm 4 (Assume a single column of text of variable sizes)를 이용한다. 참고로, 한글 출력을 정확히 표시하기 위하여 코드 페이지를 변경한 수 명령을 실행한다.
- 코드 페이지 변경: chcp 65001 (UNICODE 이용)
- 텍스트 인식 : tesseract -c preserve_interword_spaces=1 image.jpg stdout -l kor+eng --psm 4
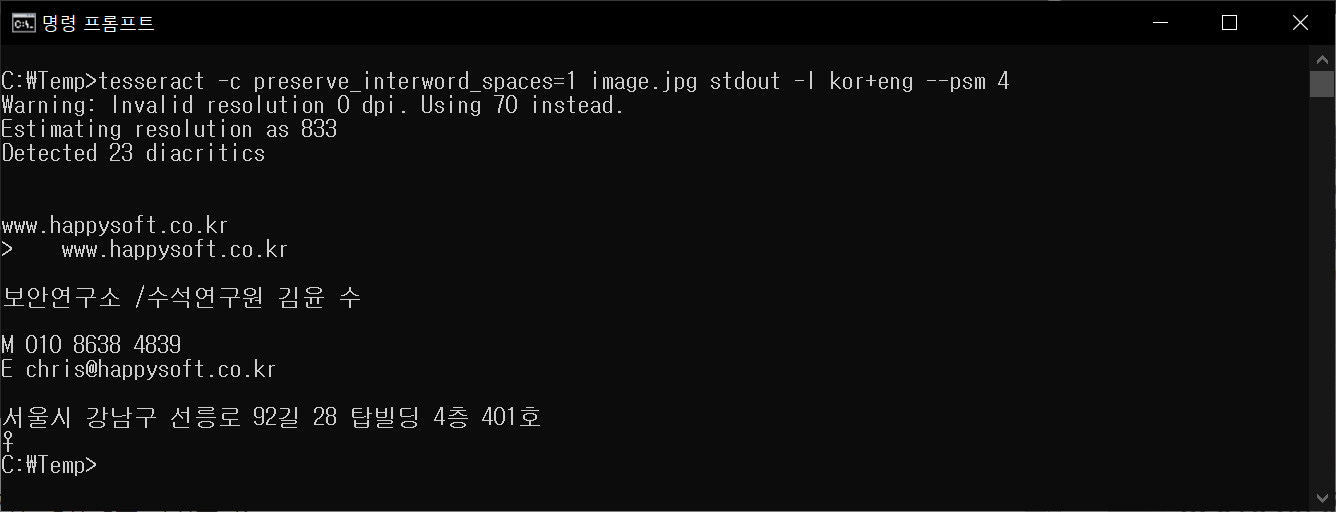
- 간단한 예제이지만 잘 동작한다.
3. Python으로 Tesseract 라이브러리 이용하기
3.1 Python-tesseract 라이브러리 설치하기
- 파이썬에서 Tesseract 라이브러리를 사용하기 위하여, Python-tesseract를 설치한다.
- GPL v3를 따르는 라이브러리 이므로, Commercial 한 제품에 사용할 수 없다. Tesseract가 아파치 2.0 라이선스를 따르는데, Wrapper class가 GPL v3인 것이 특이하다. 필요할 경우 Tesseract를 직접 이용하도록 재구성하는 것이 좋겠다.
- 홈페이지에 사용법 등이 자세히 설명되어 있어서, 쉽게 이용할 수 있다.
- https://github.com/madmaze/pytesseract
madmaze/pytesseract
A Python wrapper for Google Tesseract. Contribute to madmaze/pytesseract development by creating an account on GitHub.
github.com
- 파이선의 패키지 관리 도구인 pip를 이용하여 설치한다.
'pip install pytesseract'

3.2 Python-tesseract 라이브러리 예제
- Pyton-tesseract의 사용법은 홈페이지에 잘 나와 았으므로, 추가 설명을 생략하고 바로 간단한 에제를 만들어 본다.
- 앞서 명함을 인식한 에제를 파이썬으로 작성한다. (textExtract.py)
import pytesseract
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract'
print(pytesseract.image_to_string('C:\Temp\image.jpg',lang='kor+eng', config='-c preserve_interword_spaces=1 --psm 4'))
- python textExtract.py로 실행하여 결과를 확인한다.
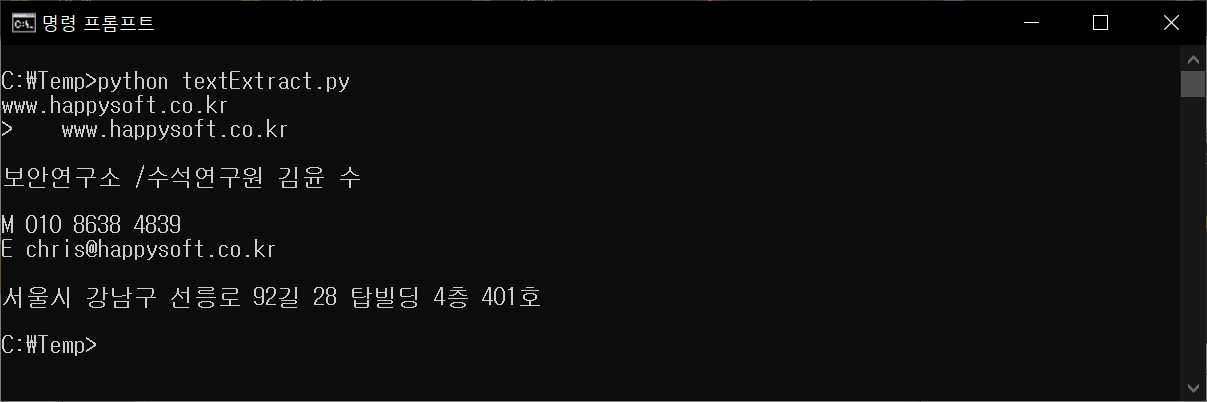
여기까지 해서, 텍스트 인식 (OCR)을 위한 대표적인 오픈소스인 Tesseract를 Python과 함께 빠르게 살펴보았다.
라이브러리를 사용하는 것은 (무척) 쉽다고 볼 수 있는데,
다양한 입력 이미지를 어떻게 좋은 품질로 처리할 수 있느냐~ 하는 것이 관건이 될 듯하다.
'DevSmile 하는 일 > 데이터분석-인공지능-자동화' 카테고리의 다른 글
| 2학기 강의 - AI딥러닝실무를 시작한다. (0) | 2024.04.24 |
|---|---|
| [YOLO] 파이썬으로 YOLOv4 빠르게 확인해 보기 (9) | 2021.02.09 |
| [수학] 데이터 분석을 본격적으로 공부해 보려 한다. (0) | 2020.01.03 |

